Gain Control By Breaking Dependencies: Task Level Part 1
The first post in the breaking dependency series provided the case for removing dependencies as a means of supporting the Agile mindset and driving control into the Agile team. Also, the post provided a general pattern for breaking dependencies.
Breaking dependencies at the task level within a team removes unnecessary waste. This creates the environment necessary for a hyper-productive, lean delivery team to emerge.
This second post in the series focuses on a key aspect of breaking task level dependencies—keeping tasks inside the team.
Keep Tasks Inside the Team
A Scrum team is a collection of individuals with all the skills necessary to deliver value to its customer. Without the necessary skills, the Scrum team will depend on an external entity and be unable to deliver value expediently.
The two anti-patterns below create dependencies and impede a team’s ability to keep tasks inside the team. These are followed by a corrective pattern that allows a team to own completing its work.
Anti-pattern 1: The Single-phase Team
Single-phase teams, as illustrated in Figure A, are common in functional organization hierarchies. These types of teams are typical in serialized development approaches such as waterfall.

Examples of single-phase teams are requirements, design, development, and testing teams. There is inherent dependency between these teams. Each team must finish their responsibility before the next team begins their responsibility.
It is a mistake to form a Scrum team with a single-phase focus. Significant waste exists in this model due to dependencies between the teams. Teamwork is diminished. Teams do not find problems introduced by upstream teams until late in the flow at the point of integration. At this point, the defects are extremely costly to fix.
No team is working on the same work item at the same time. Thus, when a downstream team needs help from an upstream team, there are two equally unsatisfying paths to resolution. For the first option, the upstream team performs a costly context-switch, stopping their work to resolve the issue. This elongates the work of the upstream team. In the second option, the upstream team tells the downstream team they must wait in queue until they free up. This wait is costly for the downstream feature.
Dependency waste is in full force with this anti-pattern.
Anti-pattern 2: The Layer Team
Every feature requires different layers of the architecture. In its simplest form, you have a front-end, middle-layer, and back-end as shown in figure B.

Layer teams form around these architectural boundaries. For instance, you could have a front-end team, a middle-layer team, and a back-end team. Each of these teams works off of a separate backlog, prioritized by a technology-focused Product Owner. For a feature to be complete it must flow through all teams as shown in Figure C.

It is unlikely that all teams are working on the same feature at the same time. As a result, feature coordination or collaboration between layer teams interrupts the flow. This causes a costly context switch. Alternatively, the requesting team is told to wait in line until the needed team is available, resulting in a costly delay.
No feature is complete until every layer team is complete with their piece of the feature puzzle. Additionally, all pieces must be integrated and working together. The delayed integration of this anti-pattern hides defects. As a result, it takes longer to resolve defects since significant time has usually passed since introducing the defect. Also, the layer team who introduced it is likely busy doing something else. Interrupting them results in a context switch. Waiting for them to finish is a wasteful delay.
Compounding the dependency problem, a single-phase testing team typically performs the integration testing of all layer team output. This team exists to test the integration of components for a feature. While the integration testing is performed, the layer teams continue developing additional layer specific components for other features in parallel. This creates further context switching and delays for the layer teams when the inevitable problems emerge during integration testing.
Finally, layer teams typically require an additional orchestration layer to manage the dependencies between the teams. Their purpose is to align each team’s individual output to integrate into a working piece of software. This adds extraneous cost and more communication channels in an attempt to tame the dependency construct of this anti-pattern.
As with single-phase teams, the wastes are numerous with the layer teams.
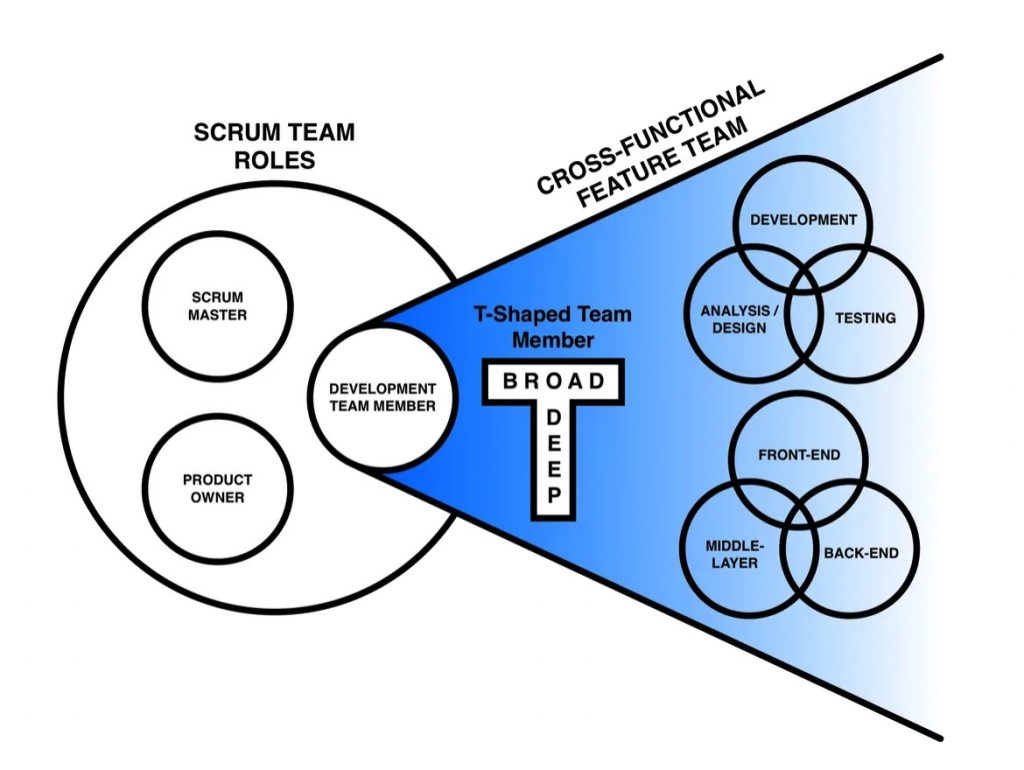
Corrective Pattern: The Cross-functional Feature Team
Fortunately, there is a simple solution for avoiding the dependencies created by the single phase team and layer team anti-patterns. It is so easy, it feels like magic or cheating. With dedicated, cross-functional feature teams, the tremendous waste inherent in the dependencies of the two anti-patterns is instantly removed.
In this pattern, the team has all the skills necessary to complete a feature. This includes skills for analysis and design, development, and testing. The team will also have skills that transcend every layer of the architecture—front-end, middle-layer, and back-end. See this pattern depicted in Figure D.
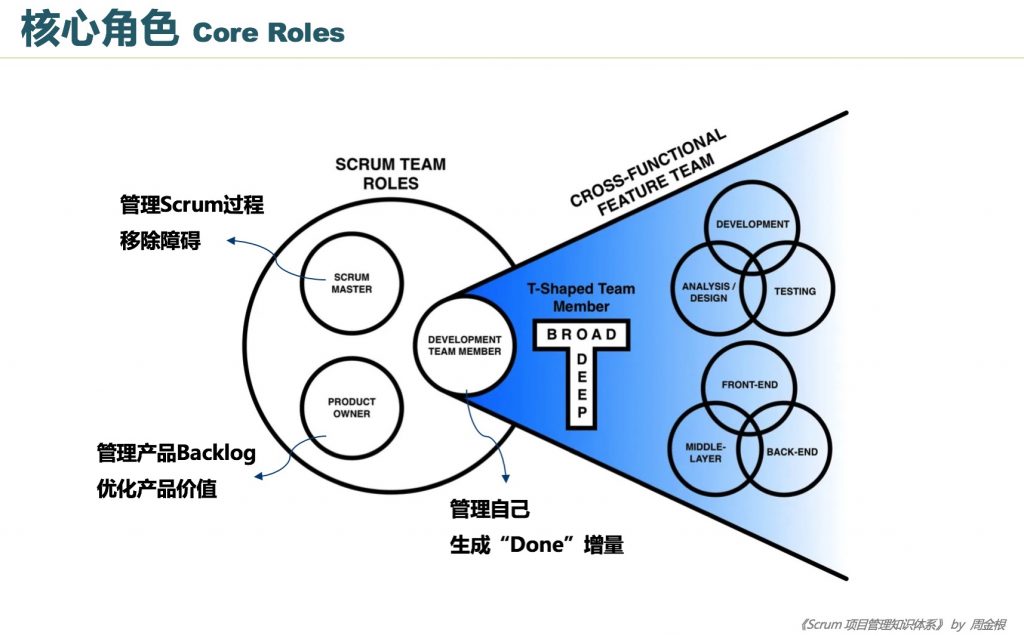
Additionally, the development team members have a goal of becoming ever increasingly T-Shaped. In other words, they develop broad cross-functional capabilities in addition to their deep specialty. This includes the delivery capabilities to work across all activities to analyze, design, develop, and test a feature. Also, the team member should strive to attain capabilities to develop all architectural layers of the feature.
With a cross-functional feature team, the team controls its destiny. It relies on nothing but itself to get the work done. The team owns every aspect of the story and has a constant focus to remove external and internal dependencies.
Sometimes a team does not have all the capabilities it needs to develop a feature. Adding people to the team with the required capability can create too large of a team. The better solution invests in building the capability within the team. If a team needs to gain skills that its team members do not possess in order to control its work, a helpful technique is cross team pairing, which is described in the prior post, How a Stable Team Grows In Capability.
For instance, if the team does not have back-end database skills, one of the development team members can cross-team pair with a database-skilled team member from another team. Performing this cross-team pairing for a few sprints will allow the team to gain the new capability for future independence.
Conclusion
There are many ways to form a team. To ensure dependencies do not develop at the task level, two team formations are not advised—single-phase teams and layer teams. These two anti-patterns add dependencies rather than remove dependencies.
Instead, you need to focus on building cross-functional feature teams. A cross-functional feature team eliminates dependencies and keeps control within the team. This allows the team to have complete control over delivering valuable working software to the end user.
Stay tuned for the next post on breaking task level dependencies—Stop Starting and Start Finishing.
转:https://coachlankford.com/2018/11/23/gain-control-by-breaking-dependencies-task-level-part-1/